Think of foundation models for industrial AI like building a new ChatGPT, just with unthinkably large amounts of timeseries data from sensors in industrial equipment. And then cross your fingers, that the resulting model develops the ability to capture generalized patterns across different asset classes and production processes.
The announcement of TimeGPT as the first foundation model for timeseries came with extreme excitement potential. In the meantime, multiple institutions have followed the pioneers from Nixtla and released their own timeseries foundation models (https://arxiv.org/pdf/2403.14735), some open-source.
Why the excitement potential? If that worked perfectly, we’d have a few less problems:
- We’d be rid of the cold start problems you encounter when shifting operational contexts.
- We could detect rare events like failures (the more critical, the rarer) based on examples of similar failures seen elsewhere.
- Transferring analytics from one asset class to a similar but different one would become almost trivial.
While TimeGPT isn’t built specifically for sensor data from manufacturing processes, Till and me curiously lined up to get our 2’000 USD of beta-tester credits and Niccolo gave it a test ride with data from real industrial equipment.
Our data was acquired during the operation of a hydraulic system consisting of a working and cooling circuit with various components, such as a pump, heat exchanger, valves, and filter. The circuits’ built-in sensors included multiple temperature, pressure, and flow sensors. We also had access to the pump motor’s electrical power consumption. Data points were logged at a maximum frequency of 0.01 Hertz, a high but not atypical raw sampling rate for sensor data in industrial use cases. Statisticians would describe our dataset as cyclo-stationary: it is cyclical, with the statistical properties between cycles such as the mean, maximum, or standard deviation being similar. Such datasets are among the most common in industrial processes, for example when a production machine manufactures a batch of identical products.
1. We failed at prompting the model to capture patterns on short and longer timescales simultaneously.
Like ChatGPT, there is a limit in the length of the input that a model is able to pay attention to. We refer to this as a context window. Throughout the past year, LLMs have made immense progress regarding this metric, which greatly increases their utility for extracting information from really large amounts of data without any engineered data preprocessing - think of models, where you can input entire books at once.The data acquired in industrial processes usually contains relevant crucial information on multiple timescales. For example, when analyzing vibration data from a failing gearbox, we might look for changes in its dominant frequencies using data sampled at a sub-millisecond timescale across timescales that are orders of magnitudes larger. Typically, we would do this by engineering meaningful “virtual sensors” from the raw time-series to enable comparisons across larger timescales.
The idea of an AI model capable of directly processing large amounts of raw timeseries data from industrial assets, eliminating the need for “engineered” analytics, sounds highly efficient, versatile, and thus extremely scalable in terms of how it can be applied to different use cases. However, we believe it will remain a pipe dream until the context windows of TimeGPT-like models become substantially longer. In our tests with different sampling rates, we observed either of two things:
- After a short window of accurate predictions, the propagation of prediction errors lead to completely useless predictions. The model was not able to capture any of the behavior in the data that was observable on a larger timescale on an order of seconds, such as the cycles.
- We downsampled the data by factors of up to 100, until it was able to capture the cyclical behavior of the data. Each predicted cycle was practically identical, because most relevant information on a shorter timescale was lost due to the heavy use of downsampling.
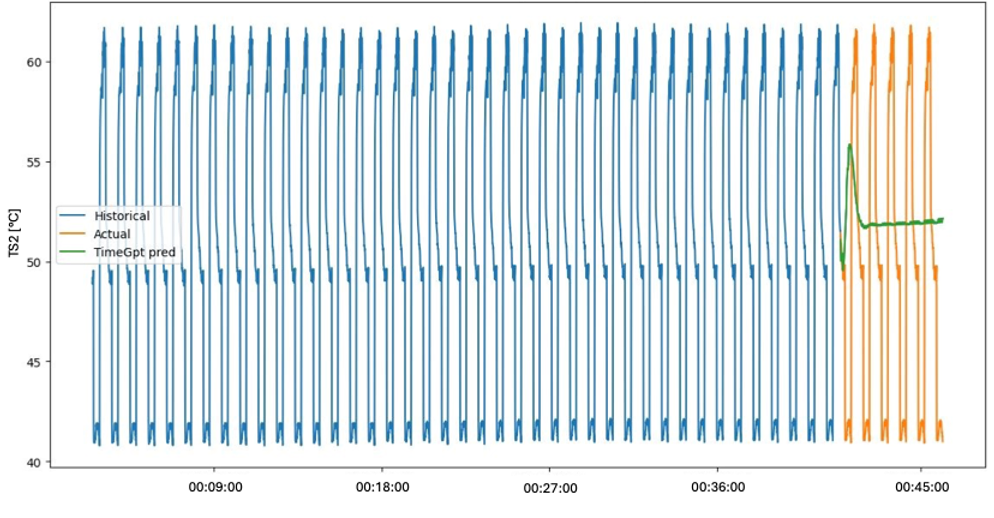
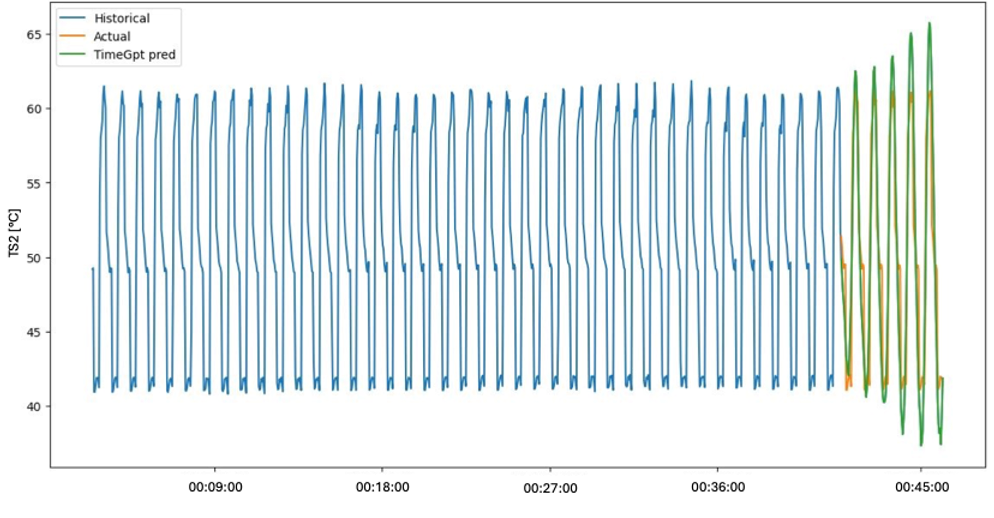
2. The model isn’t really built for multivariate data.
Timeseries data is characterized by temporal relationships: What a sensor measures now is likely influenced by what it measured prior to that and when you analyze its measurements, some insights remain hidden until taking those relationships. Even for simple components in a technical system, we are frequently able to log data from multiple sensors.And these relationships matter: For the purpose of monitoring our example pump’s operation its input and output pressures, its flow rate, and its electrical power consumption provide a solid basis for a simple analysis of its condition. Intuitively, given a specific differential pressure and flow rate, we should expect a specific electrical power consumption. Should it the pump start leaking internally, we should expect its efficiency to drop and its power consumption to increase. Remove just one of the data points from this simple model and you lose that contextual information that makes this analysis possible.
There are established algorithms like Vector Autoregression and more complicated deep learning model architectures designed to handle such so-called multivariate timeseries. However, TimeGPT (and the other foundational timeseries models we are aware of) is currently not. While you can input and forecast multiple timeseries in parallel, by design, it does not (yet) consider the meaningful interrelationships between different signals of a system. Changing this is challenging when considering how these models work, but could make foundational models much more useful for industrial AI use cases.
3. Forecasting models are of limited use when it comes to use cases around sensor data from manufacturing processes.
Between our teammates, we’ve engineered analytics solutions for well over two dozen industrial use cases, ranging from classical statistical analysis to complicated deep learning models. Depending on the objective of a use case, different families of algorithms come into question. Condition and process monitoring frequently demand for anomaly detection algorithms. Predictive quality frequently makes use of classification algorithms. Remaining useful lifetime predictions frequently make use of regression models. Only one case from the mining industry explicitly required forecasting future values of a highly inert system’s state, enabling a smarter and more efficient control of the system.
If we assume a near-perfect forecasting model, we could utilize it for some of these tasks. For example, forecasts are often used to detect anomalies by using past data to forecast the present: if the present values lie outside of the forecast’s confidence interval, they are anomalous. However, achieving accurate forecasting models for industrial timeseries data is not just hard; it’s an unreasonable undertaking, when the future heavily depends on unobserved events of its past or unpredictable events in the future, like control inputs to a system or the dynamic operational contexts of a modern factory.
We’d like to conclude by underlining that our experiments are far from a rigorous analysis of TimeGPT’s capabilities in the industrial timeseries domain. Consider them as playing around with a technology we are deeply excited about, due to its potential to revolutionize the way we approach industrial AI, created by Nixtla, a company we hold in high esteem.
Unfortunately, there is still no free lunch and we might have to spend a few more years working with what actually works today.
4. Speaking of “no free lunch”, we learned one more thing:
We burned through those 2’000 USD in credits extremely quickly at a cost per prediction that is substantially beyond what is cost-effective for most condition monitoring and process monitoring use cases we are familiar with. We should mention that Nixtla has worked out a new pricing plan in the mean time.
Looking for a standardized approach to turn your machine data into valuable insights?
Our machine analytics software PREKIT might be just what you need. It enables you to make your machines IoT-ready, manage their data at scale, connect it with your process expertise, and deploy AI-enhanced yet transparent monitoring and diagnostic tools. Just check out our homepage for more information!
And if you want to dive deeper into your use case and challenges or have any more questions, make sure to book your consultation call with one of our experts right now.





